

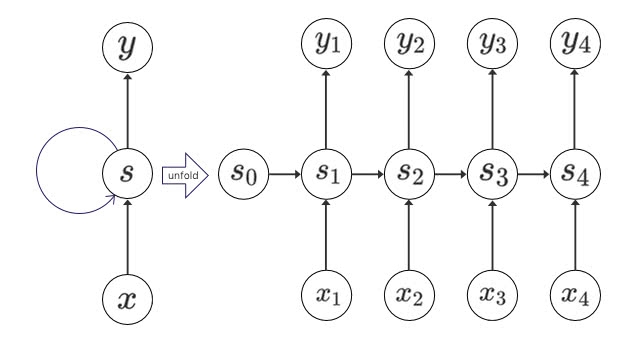
- Recurrent Neural Network
- 来月の航空会社の乗客数を予測する
- まとめ
- 参考
人の活動全般に関して言えることだが、前の文脈を前提にして理解を進めている。本を読むときは登場人物に関して知識がある状態で次の章に進む。映画を見るときもそうだ。順伝播型ニューラルネットワークでは、このような時系列を考慮した記憶域を持っていない。Recurrent Neural Networksではこういった過去の情報を考慮して未来のことを予測することができる。
この記事では、実践的な時系列予測の問題をTFLearnでLSTMネットワークを構築しながら
- Recurrent Neural Networkとは何か
- 時系列データから未来を予測する方法
- LSTMとGRUを実装する方法
を解説していく。解決しようとしている問題が、時系列予測の回帰モデルの問題に当てはまるとき、この方法を使えることを頭の中に入れておいて欲しい。
Recurrent Neural Network
Recurrent Neural Network(RNN)は、1980年代に提唱された。ニューラルネットワークの構成がよく出来ていたにもかかわらず、ここ数年までそれほど利用されることのない技術だった。学習にかかる時間が現実的ではなかったのだ。ここ数年のGPUの性能向上によって一気に普及し始めている。
時系列データを扱うRNN
RNNはニューラルネットワークのユニットに記憶域を持たせたもので、その特性上時系列データで利用される事が多い。チャットボット・翻訳などの言語モデルや売上予測などに使われる。個々の要素が順序を持っていて、並び方に意味のあるような問題が対象となる。
文を単語に区切ると、順序付きデータの入力は以下のように表現できる。
Good morningという単語列があったとき、次の単語を予測する問題は以下の表のようになる。
| 単語 | Good | morning | ? |
| 入力 | |||
| 出力 |
この場合、入力値 , があったときに、出力値 を予測することになる。
Long Short-Term Memory Networks
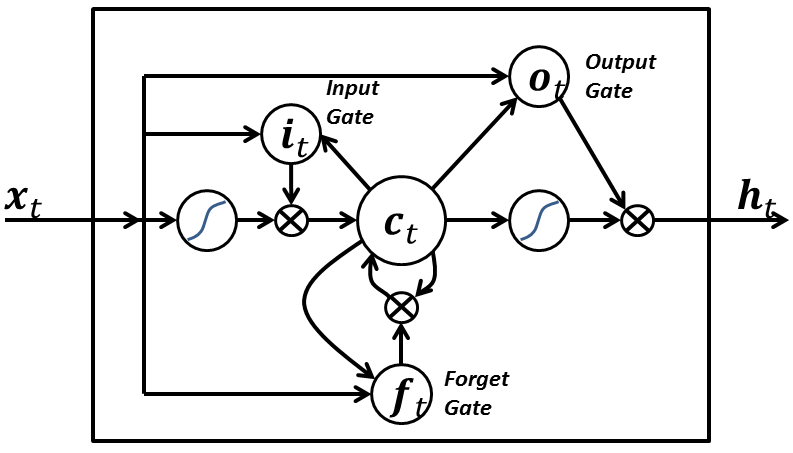
LSTM登場以前のRNNには弱点があった。長い時系列を記憶しておくことが難しかったのだ。ゲートのメカニズムを導入することで、その名の通り遠い過去のことまで覚えておくことができるようになったものだ。
上図のようにRNNセルの内部に
- 入力ゲート
- 出力ゲート
- 忘却ゲート
が存在している。忘却ゲートがあるのは、記憶域が完全に不要になるかどうかを判断するためで、過去の影響を受けなくなったことを識別するためにあるとここでは覚えておこう。
つまり、LSTMを使うべきときは遠い過去の情報まで参考にしないと予測できないような問題ということになる。
来月の航空会社の乗客数を予測する
来月の航空会社の国際線での乗客数を予測する問題を扱ってみよう。まずはデータをダウンロードしてほしい。
DataMarketからExportをクリックして「CSV(,)」を選択してダウンロードしよう。
まずはデータを確認する。headコマンドを使って最初の数行を見よう。
$ head international-airline-passengers.csv
"Month","International airline passengers: monthly totals in thousands. Jan 49 ? Dec 60"
"1949-01",112
"1949-02",118
"1949-03",132
"1949-04",129
"1949-05",121
"1949-06",135
"1949-07",148
"1949-08",148
"1949-09",136
カンマ区切りのCSVファイルとなっていて、年月が最初の列、次の列が乗客数になっている。
ファイルの末尾も確認しておこう。tailコマンドで確認できる。
$ tail international-airline-passengers.csv
"1960-06",535
"1960-07",622
"1960-08",606
"1960-09",508
"1960-10",461
"1960-11",390
"1960-12",432
International airline passengers: monthly totals in thousands. Jan 49 ? Dec 60
最後の3行には不要なデータが入っている。
TFLearnと必要なライブラリのインストール
TensorFlowは事前にインストールしておこう。
- 可視化ライブラリのmatplotlib
- データ分析ライブラリのpandas
- Deep LearningフレームワークTFLearn
をインストールする。
$ pip install matplotlib pandas tflearn
まずは乗客数のデータを可視化してみる
とにかくデータを可視化するところから始めよう。まずは、PandasでCSVファイルを読んでみて、matplotlibで可視化する。Jupyter notebookを使うと便利。
import pandas as pd
%matplotlib inline
df = pd.read_csv('international-airline-passengers.csv', engine='python', skipfooter=3)
df.plot()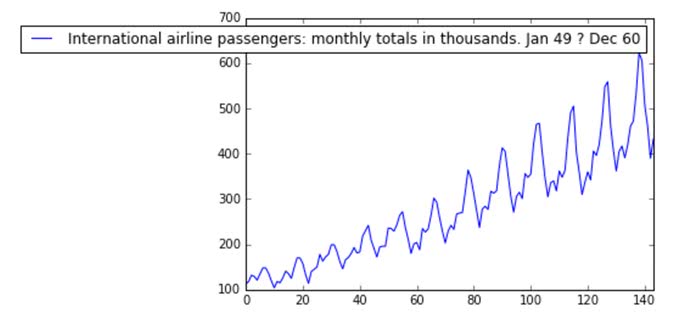
注目して欲しい部分は、12ヶ月ごとの周期で大きく乗客数が飛躍することと、全体的に需要が増加していそうだということだ。1年のうち長期休暇のときに乗客数が増えるのだろう。
LSTMネットワークを構築しよう
それでは、LSTMネットワークを構築していこう。まずは必要なモジュールをimportする。
import numpy as np
import pandas as pd
import tflearn
import matplotlib.pyplot as pltそして、先ほどと同じようにデータを読み込む。今回は時間のデータは不要なので読み込む部分の引数usecolsを1列目だけということで[1]としておこう。skipfooterのオプションを使うと、最後の無駄な行を省くことができる。
dataframe = pd.read_csv('international-airline-passengers.csv',
usecols=[1],
engine='python',
skipfooter=3)
dataset = dataframe.values
dataset = dataset.astype('float32')LSTMは入力値を0~1に正規化しておくと安定した出力が得られる。乗客数を0~1に変換しよう。
dataset -= np.min(np.abs(dataset))
dataset /= np.max(np.abs(dataset))LSTMに限らず、機械学習では訓練データとテストデータに分けてあとで評価できるようにしておくのが一般的だ。今回は67%を訓練データセット、33%をテストデータセットとして扱う。
def create_dataset(dataset, steps_of_history, steps_in_future):
X, Y = [], []
for i in range(0, len(dataset)-steps_of_history, steps_in_future):
X.append(dataset[i:i+steps_of_history])
Y.append(dataset[i + steps_of_history])
X = np.reshape(np.array(X), [-1, steps_of_history, 1])
Y = np.reshape(np.array(Y), [-1, 1])
return X, Y
def split_data(x, y, test_size=0.1):
pos = round(len(x) * (1 - test_size))
trainX, trainY = x[:pos], y[:pos]
testX, testY = x[pos:], y[pos:]
return trainX, trainY, testX, testY
steps_of_history = 1
steps_in_future = 1
X, Y = create_dataset(dataset, steps_of_history, steps_in_future)
trainX, trainY, testX, testY = split_data(X, Y, 0.33)TFLearnでLSTMネットワークを構築していこう。今回は回帰問題なので、activation関数は恒等関数にして二乗誤差を最小にするように学習させる。
net = tflearn.input_data(shape=[None, steps_of_history, 1])
net = tflearn.lstm(net, n_units=6)
net = tflearn.fully_connected(net, 1, activation='linear')
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='mean_square')
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(trainX, trainY, validation_set=0.1, batch_size=1, n_epoch=150)---------------------------------
Run id: J4TGI5
Log directory: /tmp/tflearn_logs/
---------------------------------
Training samples: 86
Validation samples: 10
--
Training Step: 86 | total loss: 0.02076
| Adam | epoch: 001 | loss: 0.02076 | val_loss: 0.05120 -- iter: 86/86
--
Training Step: 172 | total loss: 0.01732
| Adam | epoch: 002 | loss: 0.01732 | val_loss: 0.02748 -- iter: 86/86
--
こういったログがでれば学習できているはずだ。
TensorBoardで誤差を可視化する
TFLearnはバックエンドとしてTensorFlowを使っているので、TensorFlowの可視化機構TensorBoardも使えるはずだ。
model = tflearn.DNN(net, tensorboard_verbose=0)の引数tensorboard_verboseの値を0~3にすることで可視化するログレベルを調節できる。
0: 誤差と正解率
1: 誤差と正解率と勾配
2: 誤差と正解率と勾配と重み
3: 誤差と正解率と重みと活性度とスパースさ
が可視化できる。verboseのレベルを上げるとより詳細を可視化できるが、学習速度が落ちる。
$ tensorboard --logdir=/tmp/tflearn_logs
でTensorBoardを起動しよう。localhost:6006をブラウザからアクセスすれば起動できるはずだ。
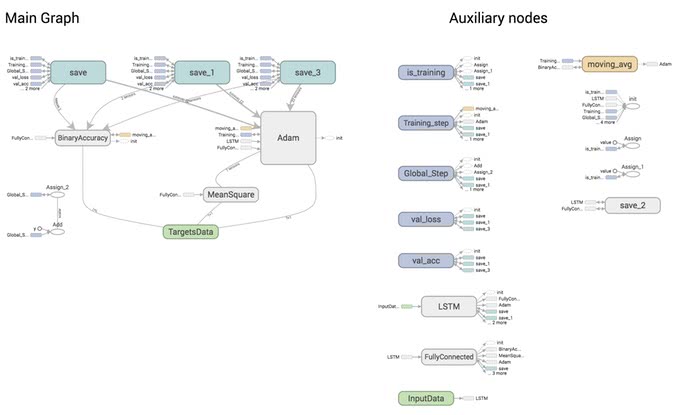
こういったフローグラフが見れたりして、デバッグなどに便利。
グラフを見ることもできるので、是非とも活用して欲しい。
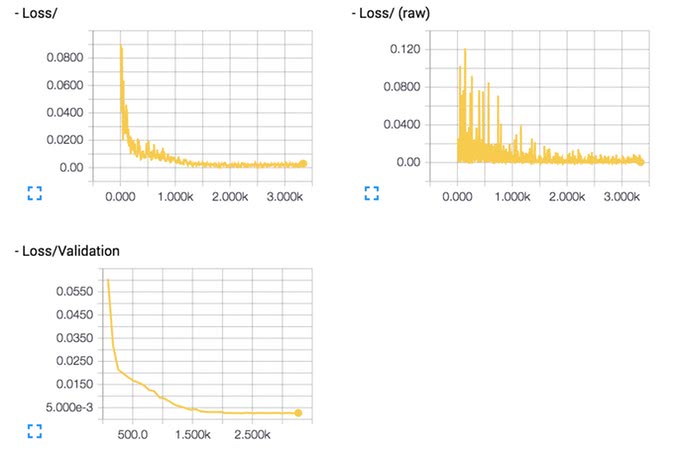
誤差が小さくなっているか、収束の速度はどうかなど見ながらハイパーパラメータを調整するといい。
時系列分析での予測精度の指標
予測や分類といった問題を解く際、設定した課題に対してどのモデルが最も適しているかを評価するための指標(評価関数)があると性能を比較しやすい。
時系列の数値予測をする際には、その指標にRMSE、RMSLEや、MAE、MAPEといったものを使うことが多い。
以下のような関数で実装できるので、どれかを選択して試しながらやってみて欲しい。
RMSE(Root Mean Squared Error)
def rmse(y_pred, y_true):
return np.sqrt(((y_true - y_pred) ** 2).mean())RMSLE(Root Mean Squared Logarithmic Error)
def rmsle(y_pred, y_true):
return np.sqrt(np.square(np.log(y_true + 1) - np.log(y_pred + 1)).mean())MAE(Mean Absolute Error)
def mae(y_pred, y_true):
return np.mean(np.abs((y_true - y_pred)))MAPE(Mean Absolute Percentage Error)
def mape(y_pred, y_true):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100結果を可視化する
それでは、予測結果を可視化してみよう。正解データを青色、訓練データを予測した結果が緑色、テストデータを予測した結果を青色でプロットしてみる。
train_predict = model.predict(trainX)
test_predict = model.predict(testX)
train_predict_plot = np.empty_like(dataset)
train_predict_plot[:, :] = np.nan
train_predict_plot[steps_of_history:len(train_predict)+steps_of_history, :] = \
train_predict
test_predict_plot = np.empty_like(dataset)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict)+steps_of_history:len(dataset), :] = \
test_predict
plt.figure(figsize=(8, 8))
plt.title('History={} Future={}'.format(steps_of_history, steps_in_future))
plt.plot(dataset)
plt.plot(train_predict_plot)
plt.plot(test_predict_plot)
plt.savefig('passenger.png')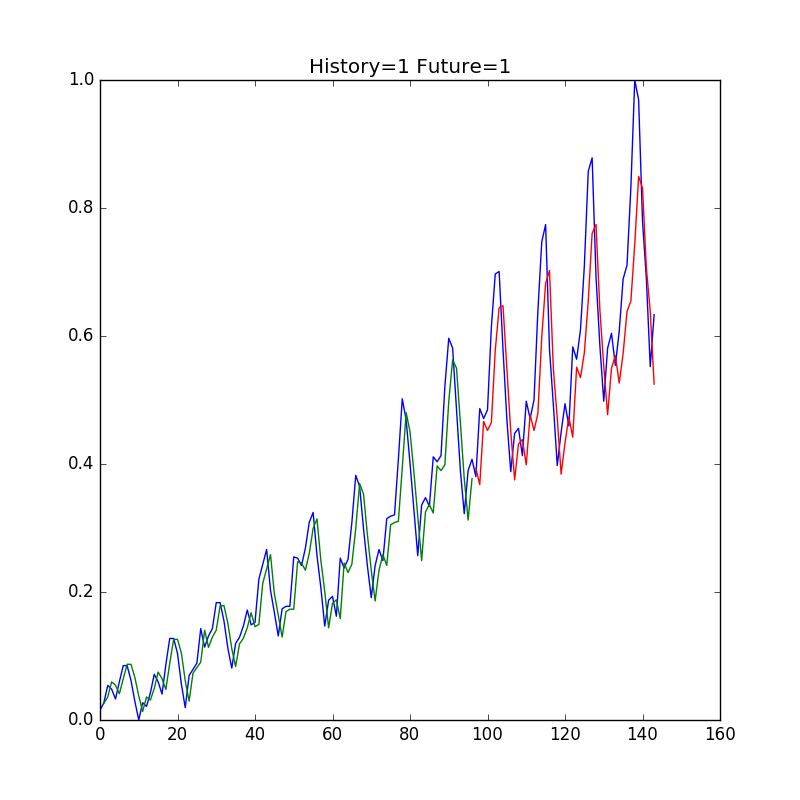
訓練データが少ない割には似通ったグラフがプロットされた。
Window幅を変えてみる
直近数回分のデータを入力値として、次の乗客数を予測することもできる。つまり、, , の値を入力値として、の値を予測する。
入力のWindow幅を3に変更してみよう。
steps_of_history = 3として実行してみる。
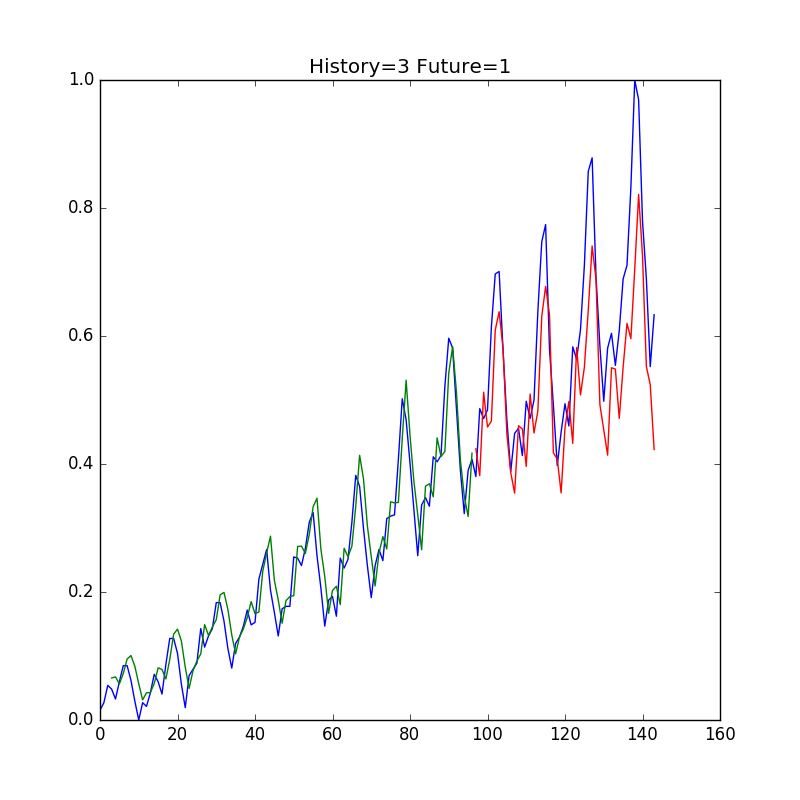
あまり改善されていない。
GRU(Gated Recurrent Unit)を使う
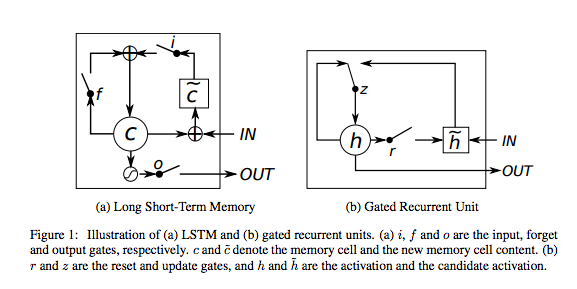
LSTMの改良版GRUを使ってみよう。これは、LSTMをさらにシンプルな構造にしたもので、忘却ゲートと入力ゲートを単一の「更新ゲート」として組み合わせている。
TFLearnでGRUを使うことは非常に簡単だ。
net = tflearn.lstm(net, n_units=6)の部分を
net = tflearn.gru(net, n_units=6)と変更するだけだ。
こちらも実行して可視化してみる。
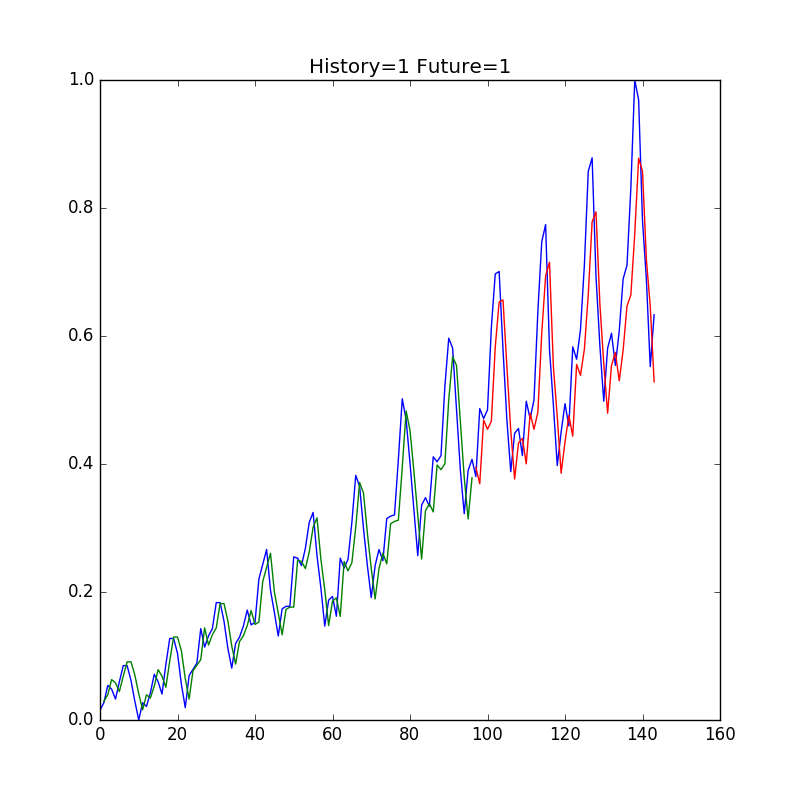
GRUの層を増やしてみる
GRUの層の数を増やしてみよう。return_seqパラメーターをTrueにして2つ繋げてみる。
net = tflearn.gru(net, n_units=6)の部分を
net = tflearn.gru(net, n_units=6, return_seq=True)
net = tflearn.gru(net, n_units=6)とするだけでいい。
実行してみよう。
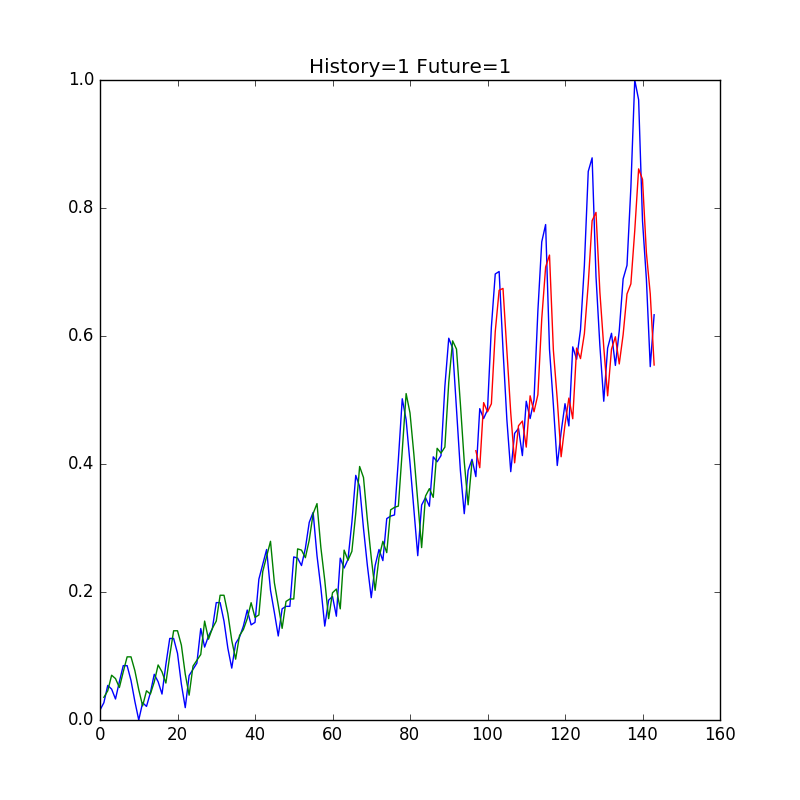
こちらは随分と推定値が実際の値に近くなったように見える。
LSTM学習のコツ
LSTMのパラメーターはどのように決定すればいいのだろうか? わかるLSTMという記事に参考になる記述があったので紹介しよう。
まず、学習率の設定は何においても重要になります。データセットによって大きく傾向が異なりますが、予測誤差が一気に改善する特異な地点が存在することがわかります。論文中ではまず高い学習率(1程度)から始めて、性能の改善が停止するたびに10で割る大雑把な探索が推奨されています。 一方で、隠れ層の数については非常にわかりやすい傾向が出ています。期待通り、隠れ層の数を増やせば増やすほど性能は改善しますが、そのトレードオフとして実行時間が増加します。なお、図表に示されてはいませんが、モーメンタムの値は今回の解析では値の設定による性能の変化はなかったと報告されています。BPTTの打ち切りステップ数についての言及はこの論文ではありませんでしたが、直感的には獲得したい長期依存の長さとタスクの実行時間とのバランスを取るのが標準的な戦略だと思われます。
まとめ
サンプル数は少なかったが、実践的な例題を通してLSTMからGRUまで試してみた。
RNNを使うことで、順伝播型ニューラルネットワークでは出来なかった順序列を扱うようなニューラルネットワークも構築することができる。 時系列予測や言語モデルなどにもすでに応用されていて、新しいニューラルネットのアーキテクチャも次々と提案されるようになった。
今後もまだまだ発展するだろうと感じている。
{kind=link}